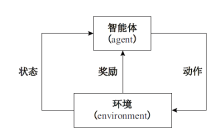
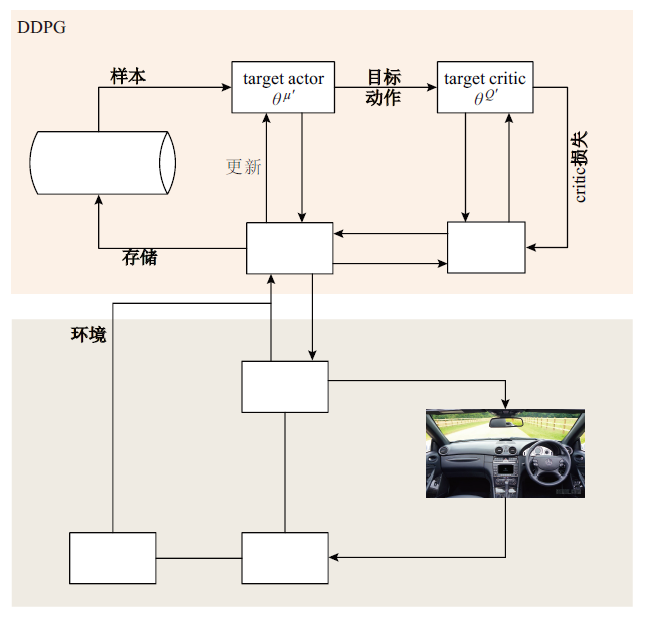
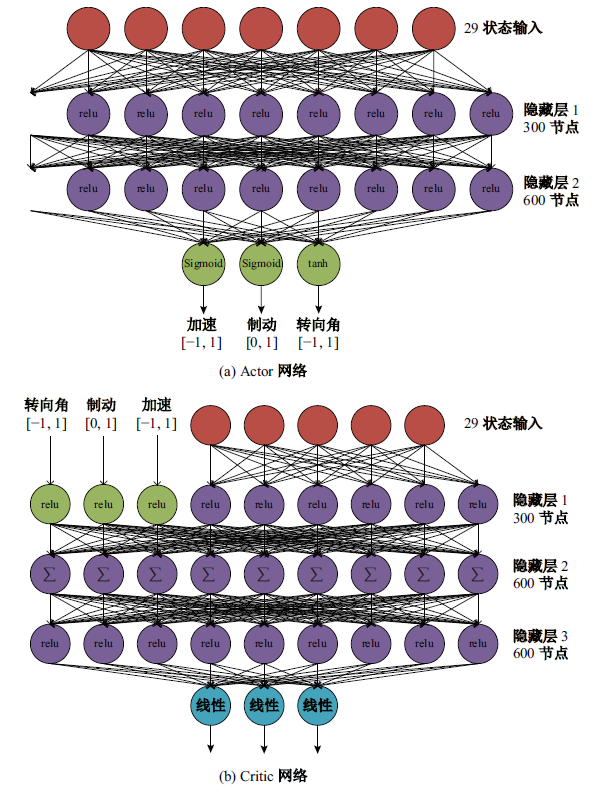
| [1] |
王奕博. 自动驾驶及其关键技术的研究[J]. 通讯世界, 2019, 26(10): 279-280.
|
| [2] |
Mnih V, Kavukcuoglu K, Silver D, et al. Playing Atari with deep reinforcement learning[J]. Computer Science, 2013, 68(440): 22-33.
|
| [3] |
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
|
| [4] |
何佳, 戎辉, 王文扬, 等. 百度谷歌无人驾驶汽车发展综述[J]. 汽车电器, 2017(12): 19-21.
|
| [5] |
Bojarski M, Testa D D, Dworakowski D, et al. End to end learning for self-driving cars[EB/OL]. [2022-10-03]. https://blog.csdn.net/kuvinxu/article/details/114288007.
|
| [6] |
Karavolos D. Q-learning with heuristic exploration in Simulated Car Racing[M]. Cambridge, MA: MIT Press, 2013.
|
| [7] |
Jaritz M, Charette R D, Toromanoff M, et al. End-to-end race driving with deep reinforcement learning[C]// International Conference on Robotics and Automation. 2018: 2070-2075.
|
| [8] |
Lau Y P. Using keras and deep deterministic policy gradient to play torcs[EB/OL]. [2022-10-12] https://yanpanlau.github.io/2016/10/11/Torcs.
|
| [9] |
Kaushik M, Prasad V, Krishna K M, et al. Overtaking maneuvers in simulated highway driving using deep reinforcement learning[C]// Intelligent Vehicles Symposium. 2018: 1885-1890.
|
| [10] |
张斌, 何明, 陈希亮, 等. 改进DDPG算法在自动驾驶中的应用[J]. 计算机工程与应用, 2019, 55(10): 1-10.
|
| [11] |
Lange S, Riedmiller M, Voigtlander A. Autonomous reinforcement learning on raw visual input data in a real world application[EB/OL]. [2022-11-04]. https://xueshu.baidu.com/usercenter/paper/show?paperid=9ab0c6bb6f20e9e261c075db5faac598&site=xueshu_se.
|
| [12] |
Huval B, Wang T, Tandon S, et al. An empirical evaluation of deep learning on highway driving[EB/OL]. [2022-09-25]. https://xueshu.baidu.com/usercenter/paper/show?paperid=ec871a6ea63bb711dcebc6d9830ddbb4&site=xueshu_se.
|
| [13] |
Huang W H, Braghin F, Wang Z, et al. Learning to drive via apprenticeship learning and deep reinforcement learning[C]// International Conference on Tools with Artificial Intelligence. 2019: 1536-1540.
|
| [14] |
Chae H, Kang C M, Kim B D, et al. Autonomous braking system via deep reinforcement learning[EB/OL]. [2022-09-16].https://arxiv.org/abs/1702.02302.
|
| [15] |
Mnih V, Badia A P, Mirza M, et al. Asynchronous methods for deep reinforcement learning[EB/OL]. [2022-11-22].https://blog.csdn.net/jiayoudangdang/article/details/113936242.
|
| [16] |
Kendall A, Hawke J, Janz D, et al. Learning to drive in a day[C]// International Conference on Robotics and Automation. 2019: 8248-8254.
|
| [17] |
Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2022-10-18].https://www.cnblogs.com/lucifer1997/p/13890666.html.
|
| [18] |
Sutton R S, Barto A G. Reinforcement learning: an introduction[M]. Cambridge: MIT Press, 2018: 27-161.
|
| [19] |
Schaul T, Quan J, Antonoglou I, et al. Prioritized experience replay[EB/OL]. [2022-11-08].https://wenku.baidu.com/view/d09977b811661ed9ad51f01dc281e53a59025114.html?_wkts_=1669776885058&bdQuery=Prioritized+experience+replay.
|
 ), 刘千红, 季泽宇
), 刘千红, 季泽宇