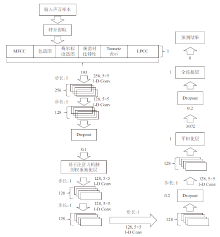
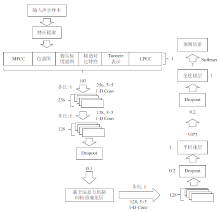
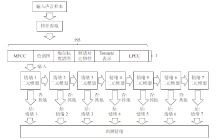
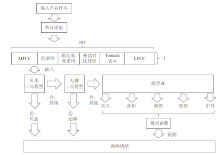
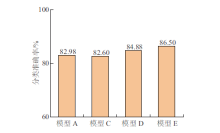
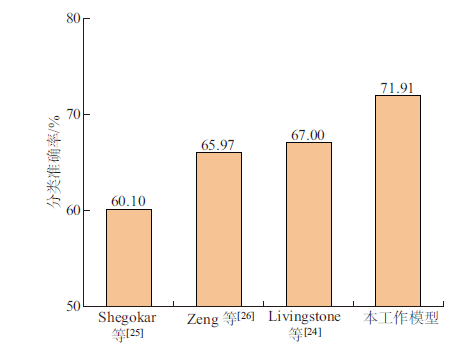
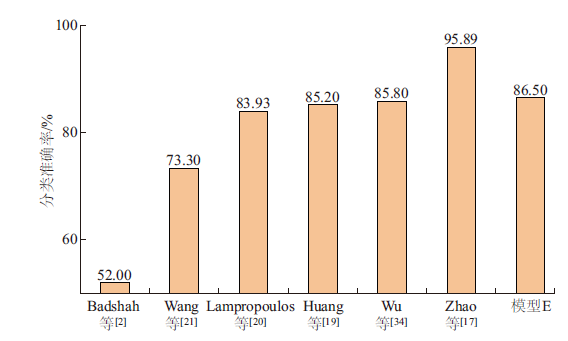
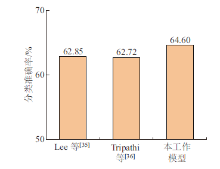
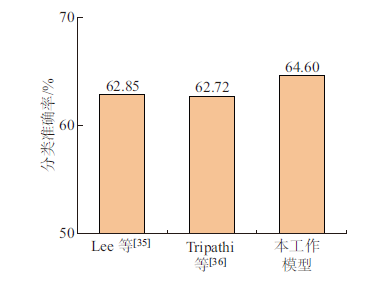
| [1] |
Han I T K, Yu D. Speech emotion recognition using deep neural network and extreme learning machine[C]// Proceedings of the Interspeech. 2014: 223-227.
|
| [2] |
Badshah A M, Ahmad J, Rahim N, et al. Speech emotion recognition from spectrograms with deep convolutional neural network[C]// 2017 International Conference on Platform Technology and Service, IEEE. 2017: 1-5.
|
| [3] |
Mittal S, Agarwal S, Nigam M J. Real time multiple face recognition: a deep learning approach[C]// Proceedings of the 2018 International Conference on Digital Medicine and Image Processing, ACM. 2018: 70-76.
|
| [4] |
Bae H S, Lee H J, Lee S G. Voice recognition based on adaptive mfcc and deep learning[C]// 2016 IEEE 11th Conference on Industrial Electronics and Applications. 2016: 1542-1546.
|
| [5] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778.
|
| [6] |
Huang K Y, Wu C H, Hong Q B, et al. Speech emotion recognition using deep neural network considering verbal and nonverbal speech sounds[C]// 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. 2019: 5866-5870.
|
| [7] |
Lim W, Jang D, Lee T. Speech emotion recognition using convolutional and recurrent neural networks[C]// Signal and Information Processing Association Annual Summit and Conference, IEEE. 2016: 1-4.
|
| [8] |
Trigeorgis G, Ringeval F, Brueckner R, et al. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network[C]// 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. 2016: 5200-5204.
|
| [9] |
Mirsamadi S, Barsoum E, Zhang C. Automatic speech emotion recognition using recurrent neural networks with local attention[C]// 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. 2017: 2227-2231.
|
| [10] |
Xie Y, Liang R, Liang Z, et al. Speech emotion classification using attention-based LSTM[J]. IEEE-ACM Transactions on Audio Speech and Language Processing, 2017, 27 (11): 1675-1685.
|
| [11] |
Tarantino L, Garner P N, Lazaridis A. Self-attention for speech emotion recognition[C]// Proceedings of the Interspeech. 2019: 2578-2582.
|
| [12] |
Li R, Wu Z, Jia J, et al. Towards discriminative representation learning for speech emotion recognition[C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. 2019: 5060-5066.
|
| [13] |
韩文静, 李海峰, 阮华斌, 等. 语音情感识别研究进展综述[J]. 软件学报, 2014, 25(1): 37-50.
|
| [14] |
刘振焘, 徐建平, 吴敏, 等. 语音情感特征提取及其降维方法综述[J]. 计算机学报, 2018, 41(12): 2833-2851.
|
| [15] |
Niu Y F, Zou D S, Niu Y D, et al. Improvement on speech emotion recognition based on deep convolutional neural networks[C]// Proceedings of the 2018 International Conference on Computing and Artificial Intelligence. 2018: 13-18.
|
| [16] |
Burkhardt F, Paeschke A, Rolfes M, et al. A database of german emotional speech[C]// Ninth European Conference on Speech Communication and Technology. 2005: 1517-1520.
|
| [17] |
Zhao J, Mao X, Chen L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks[J]. Biomedical Signal Processing and Control, 2019, 47: 312-323.
|
| [18] |
Demircan S, Kahramanli H. Application of fuzzy C-means clustering algorithm to spectral features for emotion classification from speech[J]. Neural Computing & Applications, 2018, 29: 59-66.
|
| [19] |
Huang Z, Dong M, Mao Q, et al. Speech emotion recognition using CNN[C]// Proceedings of the 22nd ACM International Conference on Multimedia. 2014: 801-804.
|
| [20] |
Lampropoulos A S, Tsihrintzis G A. Evaluation of MPEG-7 descriptors for speech emotional recognition[C]// 2012 Eighth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, IEEE. 2012: 98-101.
|
| [21] |
Wang K, An N, Li B N, et al. Speech emotion recognition using fourier parameters[J]. IEEE Transactions on Affective Computing, 2015, 6: 69-75.
|
| [22] |
Chatziagapi A, Paraskevopoulos G, Sgouropoulos D, et al. Data augmentation using gans for speech emotion recognition[C]// Proceedings of the Interspeech. 2019: 171-175.
|
| [23] |
Yoon S, Byun S, Jung K. Multimodal speech emotion recognition using audio and text[C]// 2018 IEEE Spoken Language Technology Workshop. 2018: 112-118.
|
| [24] |
Livingstone S R, Russo F A. The Ryerson audio-visual database of emotional speech and song (RAVDESS): a dynamic, multimodal set of facial and vocal expressions in North American English[J]. PLoS One, 2018, 13: e0196391.
|
| [25] |
Shegokar P, Sircar P. Continuous wavelet transform based speech emotion recognition[C]// 2016 10th International Conference on Signal Processing and Communication Systems, IEEE. 2016: 1-8.
|
| [26] |
Zeng Y N, Mao H, Peng D Z, et al. Spectrogram based multi-task audio classification[J]. Multimedia Tools and Applications, 2019, 78: 3705-3722.
|
| [27] |
Popova A S, Rassadin A G, Ponomarenko A. Emotion recognition in sound[C]// International Conference on Neuroinformatics. 2017: 117-124.
|
| [28] |
McFee B, Raffel C, Liang D, et al. Librosa: audio and music signal analysis in python[C]// Proceedings of the 14th Python in Science Conference. 2015: 18-25.
|
| [29] |
Stevens S S, Volkmann J, Newman E B. A scale for the measurement of the psychological magnitude pitch[J]. Journal of the Acoustical Society of America, 1937, 8: 185-190.
|
| [30] |
Beigi H. Fundamentals of speaker recognition[M]. New York: Springer Science and Business Media Inc, 2011.
|
| [31] |
Jiang D N, Lu L, Zhang H J, et al. Music type classification by spectral contrast feature[C]// 2002 IEEE International Conference on Multimedia and Expo. 2002: 113-116.
|
| [32] |
Harte C, Sandler M, Gasser M. Detecting harmonic change in musical audio[C]// Proceedings of the 1st ACM Workshop on Audio and Music Computing Multimedia. 2006: 21-26.
|
| [33] |
Busso C, Bulut M, Lee C C, et al. IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42: 335.
|
| [34] |
Wu S, Falk T H, Chan W Y. Automatic speech emotion recognition using modulation spectral features[J]. Speech Communication, 2011, 53: 768-785.
|
| [35] |
Lee J, Tashev I. High-level feature representation using recurrent neural network for speech emotion recognition[C]// Sixteenth Annual Conference of the International Speech Communication Association. 2015: 1537-1540.
|
| [36] |
Tripathi S, Beigi H. Multi-modal emotion recognition on IEMOCAP dataset using deep learning[J]. CoRRabs, 2018(4): 05788.
|
| [37] |
Chen M, He X, Yang J, et al. 3-D convolutional recurrent neural networks with attention model for speech emotion recognition[J]. IEEE Signal Processing Letters, 2018, 25: 1440-1444.
|
| [38] |
Kim Y, Lee H, Provost E M. Deep learning for robust feature generation in audiovisual emotion recognition[C]// 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. 2013: 3687-3691.
|
| [39] |
Lakomkin E, Weber C, Magg S, et al. Reusing neural speech representations for auditory emotion recognition[C]// The 8th International Joint Conference on Natural Language Processing. 2018.
|
 )
)