Journal of Shanghai University(Natural Science Edition) ›› 2018, Vol. 24 ›› Issue (5): 730-744.doi: 10.12066/j.issn.1007-2861.1843
• Research Articles • Previous Articles Next Articles
CHEN Yue1, DONG Hongbin2, TAN Chengyu1, LIANG Yiwen1( )
)
Received:2016-09-23
Online:2018-10-30
Published:2018-10-26
Contact:
LIANG Yiwen
E-mail:ywliang@whu.edu.cn
CLC Number:
CHEN Yue, DONG Hongbin, TAN Chengyu, LIANG Yiwen. Application of data provenance in multi-version documents retrieval[J]. Journal of Shanghai University(Natural Science Edition), 2018, 24(5): 730-744.

Fig. 1
Intuitive overview of PROV"


Fig. 2
Typical scenes of the teaching courseware version changes"

Table 1
Entity vocabularies"
 |
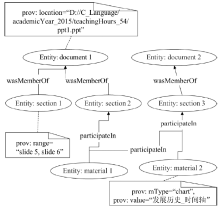
Fig. 3
Example of a entity model"
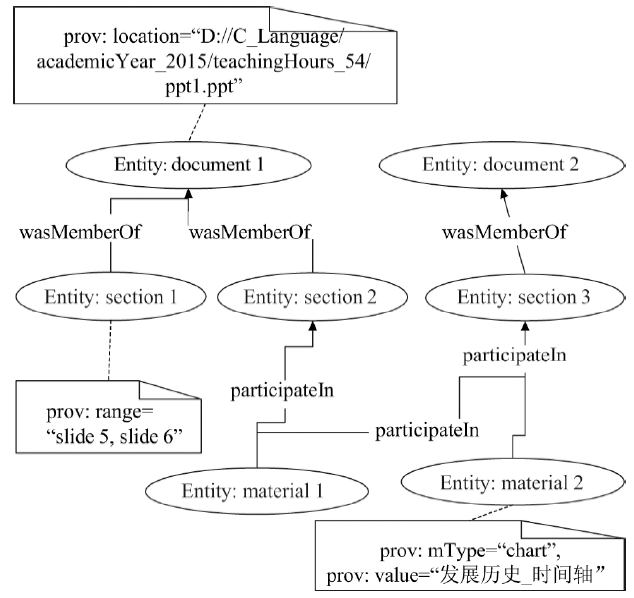
Table 2
Activity vocabularies"
 |

Fig. 4
Example of a activity model"
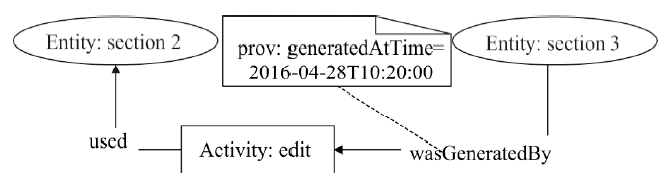

Fig. 5
Example of a agent model"
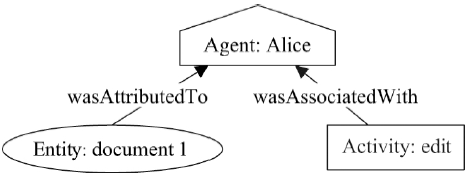
Table 3
Relations vocabularies"
 |
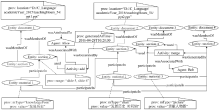
Fig. 6
Fine-grained PROV model of multi-version documents"
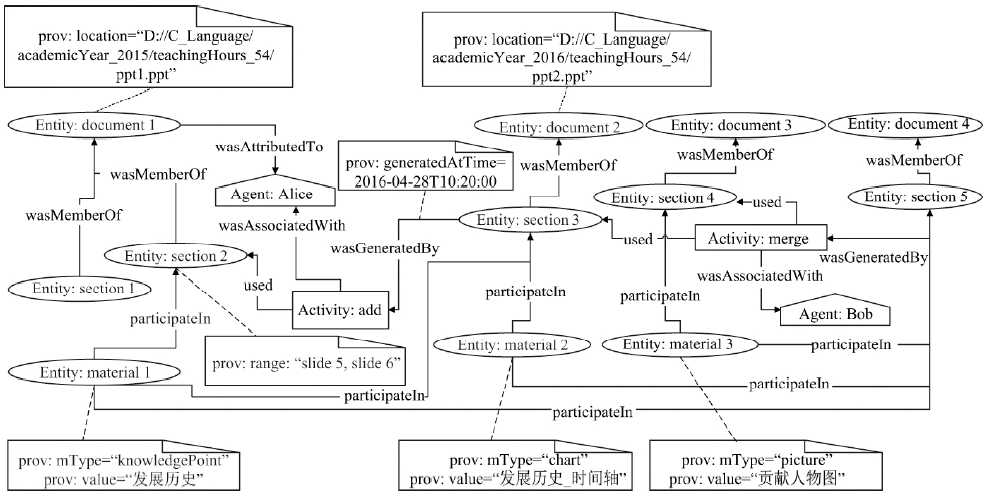
Table 4
Definition and uniqueness constraints"
 |
Table 5
Impossibility constraints and type constraints"
 |

Fig. 7
Visual results"
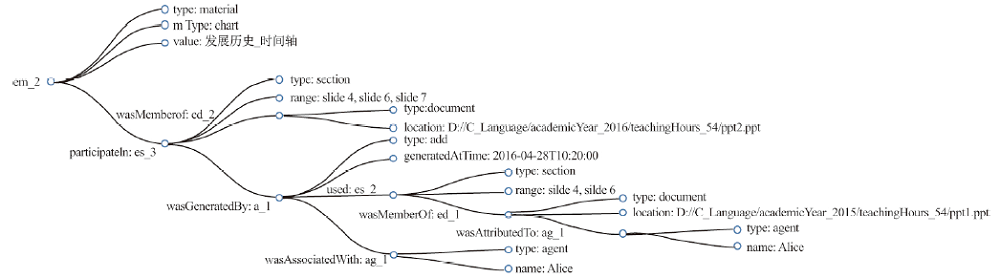

Fig. 8
Part of the visual results in Fig.7"


Fig. 9
Part of the visual results in Fig.8"
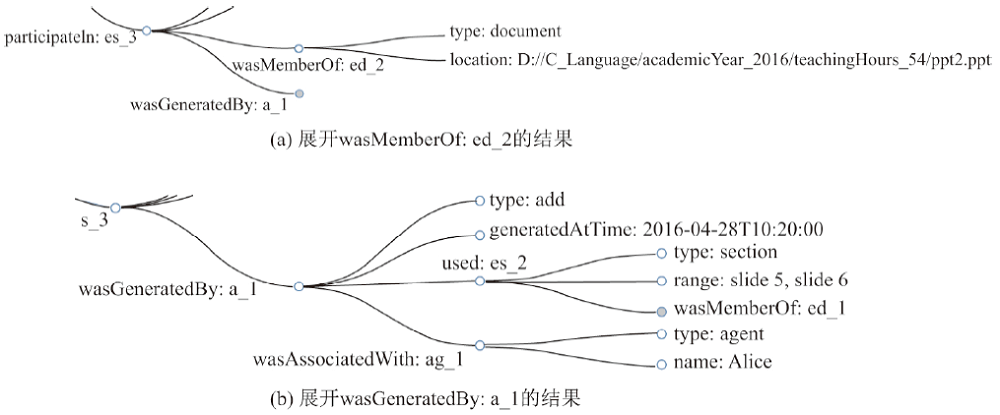

Fig. 10
Framework overview of the experimental system"
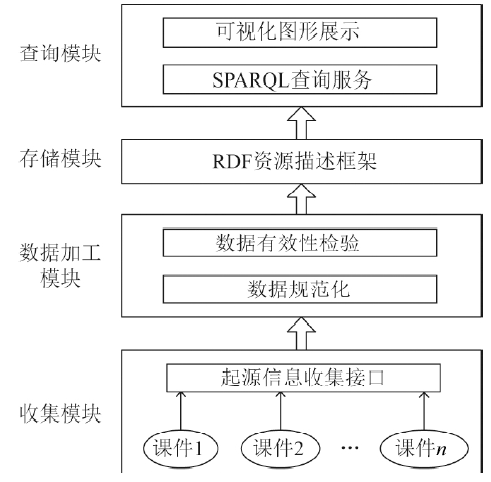
Table 6
Parameters of the experiment"
 |

Fig. 11
Experimental data statistics"

Table 7
Experimental data statistics and analysis"
 |
| [1] | Lyman P, Varian H R. How much information 2003 [EB/OL]. (2003-10-27)[2016-10-05]. http://www2.sims.berkeley.edu/research/projects/how-much-info. |
| [2] | Blanc-Brude T, Scapin D L. What do people recall about their documents: implications for desktop search tools[C]// Proceedings of the 12th International Conference on Intelligent User Interfaces, ACM. 2007: 102-111. |
| [3] | Shah S, Soules C A N, Ganger G R, et al. Using provenance to aid in personal file search[C]// USENIX Annual Technical Conference. 2007: 171-184. |
| [4] |
Soules C A N, Ganger G R. Connections: using context to enhance file search[J]. ACM SIGOPS Operating Systems Review, 2005,39(5):119-132.
doi: 10.1145/1095809.1095822 |
| [5] | Stumpf S, Fitzhenry E, Dietterich T G. The use of provenance in information retrieval[C]// Workshop on Principles of Provenance. 2007: 20. |
| [6] | Chau D H, Myers B, Faulring A. Feldspar: a system for finding information by association[C]// Proceedings of Personal Information Management. 2008: 131-138. |
| [7] | 戴超凡, 王涛, 张鹏程. 数据起源技术发展研究综述[J]. 计算机应用研究, 2010,27(9):3215-3221. |
| [8] | Rinck M, Hinze A, Bainbridge D, et al. Document DNA: content centric provenance data tracking in documents[C]// Proceedings of the 37th Australasian Computer Science Conference. 2014: 57-66. |
| [9] | Lu C T, Shukla M, Subramanya S H, et al. Performance evaluation of desktop search engines[C]// IEEE International Conference Information Reuse and Integration. 2007: 110-115. |
| [10] | Jensen C, Lonsdale H, Wynn E, et al. The life and times of files and information: a study of desktop provenance[C]// Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, ACM. 2010: 767-776. |
| [11] | Muniswamy-Reddy K K, Holland D A, Braun U, et al. Provenance-aware storage systems[C]// USENIX Annual Technical Conference, General Track. 2006: 43-56. |
| [12] | Dragunov A N, Dietterich T G, Johnsrude K, et al. TaskTracer: a desktop environment to support multi-tasking knowledge workers[C]// Proceedings of the 10th International Conference on Intelligent User Interfaces, ACM. 2005: 75-82. |
| [13] | Yamamoto K, Kuriyama T, Shigemori H, et al. Provenance based retrieval: file retrieval system using history of moving and editing in user experience[C]// Computer Software and Applications Conference. 2011: 618-625. |
| [14] |
Ball R. Don't search, just show me what I did: visualizing provenance of documents and applications[J]. International Journal of Human-Computer Interaction, 2013,29(3):156-168.
doi: 10.1080/10447318.2012.701569 |
| [15] | Luc M, Paolo M. PROV-DM: the PROV data model [EB/OL]. [2016-10-05]. https://www.w3.org/TR/2013/REC-prov-dm-20130430/. |
| [16] | Paul G, Luc M. PROV-overview: an overview of the PROV family of docu- ments [EB/OL]. [2016-10-05]. https://www.w3.org/TR/2013/NOTE-prov-overview-20130430/. |
| [17] | Moreau L, Freire J, Futrelle J, et al. The open provenance model: an over- view[C]// International Provenance and Annotation Workshop. 2008: 323-326. |
| [18] | 倪静, 孟宪学. PROV数据溯源模型及Web应用[J]. 图书情报工作, 2014,58(3):13-19. |
| [19] | Tom D N, James C, Paolo M, et al. Constraints of the PROV data model [EB/OL]. [2016-10-05]. https://www.w3.org/TR/2013/REC-prov-constraints-20130430/. |
| [20] | Eric P, Andy S. SPARQL query language for RDF [EB/OL]. [2016-10-05]. https://www.w3.org/TR/rdf-sparql-query/. |
| [1] | Yechen YANG, Yueli HU, Jie XU, Wenlong CHENG, Huaibo YU. Location method based on improved Gaussian filter and adaptive estimation for weighted environment parameter [J]. Journal of Shanghai University(Natural Science Edition), 2019, 25(5): 701-711. |
| [2] | Chen WEI, Lu ZHEN, Qiangyuan CHEN. Empirical study on the influencing factors of labor migration: a case study of Shanghai [J]. Journal of Shanghai University(Natural Science Edition), 2019, 25(5): 817-825. |
| [3] | TIAN Feng, DAI Shuaifan, DONG Fenglong, ZHANG Zhiyi, CHU Lingwei. Effect of crossing event in VR on perception of the audience [J]. Journal of Shanghai University(Natural Science Edition), 2018, 24(4): 535-544. |
| [4] | DAI Shuaifan1, TIAN Feng1,2, HUANG Chao1, TANG Haifeng3, Lü Wei4. Survey on visual comfort of 3D movies [J]. Journal of Shanghai University(Natural Science Edition), 2017, 23(3): 364-377. |
| [5] | LIU Yinlong, XIA Tiecheng, LIU Zeyu. New exact solutions of some nonlinear fractional partial differential equation [J]. Journal of Shanghai University(Natural Science Edition), 2016, 22(4): 469-476. |
| [6] | . Ant Colony Optimization Routing Based on Congestion Control in WSNs [J]. Journal of Shanghai University(Natural Science Edition), 2012, 18(6): 551-554. |
| [7] | ZHENG He,XIE Ya-nan,WAN Zhi-long,LIU Wen-yuan. Improved VIE Rainfall Retrieval Algorithm Based on SAR Measurements [J]. Journal of Shanghai University(Natural Science Edition), 2012, 18(5): 464-469. |
| [8] | JIN Yan-liang,ZHANG Yong,XUE Yong,ZHANG Zhen. Location Aided Routing Protocol Based on Congestion Control in Wireless Multimedia Sensor Network [J]. Journal of Shanghai University(Natural Science Edition), 2012, 18(3): 227-230. |
| [9] | LI Feng, MENG Lian-Qin. Improved Adaptive Domain Decomposition Finite Difference Time- Domain Method for Solving 3D EM Problems [J]. Journal of Shanghai University(Natural Science Edition), 2011, 17(6): 713-718. |
| [10] | ZHANG Kai yan;MO Yun hui;DENG Zhaoyi;et al . Multi object Fuzzy Reliability Optimization of Planar Gear Transmission Based on Improved Genetic Algorithm [J]. Journal of Shanghai University(Natural Science Edition), 2007, 13(1): 22-27 . |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||