上海大学学报(自然科学版) ›› 2022, Vol. 28 ›› Issue (2): 179-200.doi: 10.12066/j.issn.1007-2861.2316
• 特邀综述 • 下一篇
彭亚新( ), 赵倩
), 赵倩
收稿日期:2021-03-26
出版日期:2022-04-30
发布日期:2022-04-28
通讯作者:
彭亚新
E-mail:yaxin.peng@shu.edu.cn
作者简介:彭亚新(1979--), 女, 教授, 博士生导师, 博士,研究方向为数学图像分析、数据挖掘等.E-mail: yaxin.peng@shu.edu.cn基金资助:
PENG Yaxin(), ZHAO Qian
Received:2021-03-26
Online:2022-04-30
Published:2022-04-28
Contact:
PENG Yaxin
E-mail:yaxin.peng@shu.edu.cn
摘要:
骨架数据是通过对动作的空间几何位置进行编码获取,可以避免冗余背景信息的干扰, 是动作识别领域常用的数据类型之一.现有骨架数据的动作识别主要分为经典的骨架数据表征和基于深度学习的骨架动作识别应用.相较于传统欧氏度量下的识别方法,流形为更好地研究非线性结构提供了重要数学工具. 然而,目前仍缺乏利用流形假设对骨架数据进行动作识别的相关总结. 因此,从骨架表示、轨迹时间对齐、动作序列表征以及动作分类 4 个关键步骤出发,系统地总结了基于流形假设的动作识别工作,对比了各项工作在基准数据集上的表现. 最后,根据当前动作识别工作的发展趋势,对流形假设在动作识别方向上的进一步改进进行了展望.
中图分类号:
彭亚新, 赵倩. 基于流形假设的骨架序列动作识别算法[J]. 上海大学学报(自然科学版), 2022, 28(2): 179-200.
PENG Yaxin, ZHAO Qian. Skeleton-based action recognition by manifold assumption[J]. Journal of Shanghai University(Natural Science Edition), 2022, 28(2): 179-200.

图1
动作识别中涉及的数据类型"

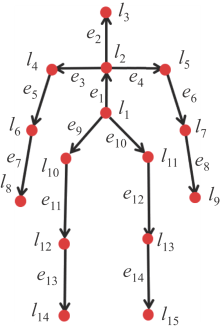
图2
骨架图"
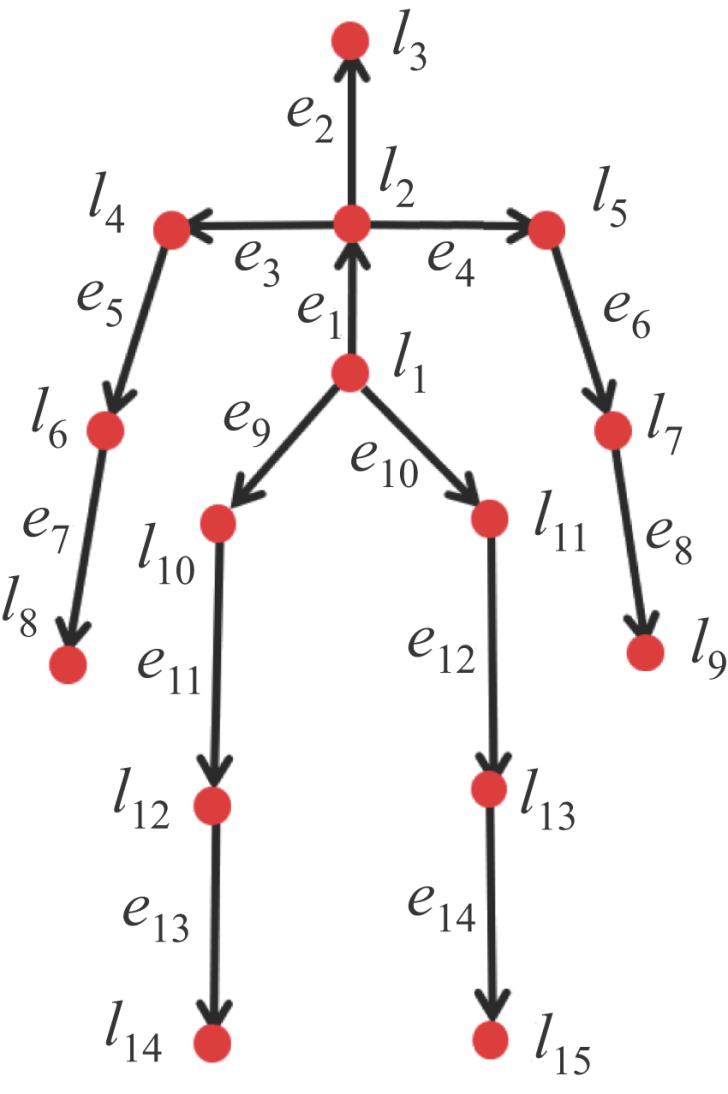
图3
将骨架序列表示为流形上的轨迹"
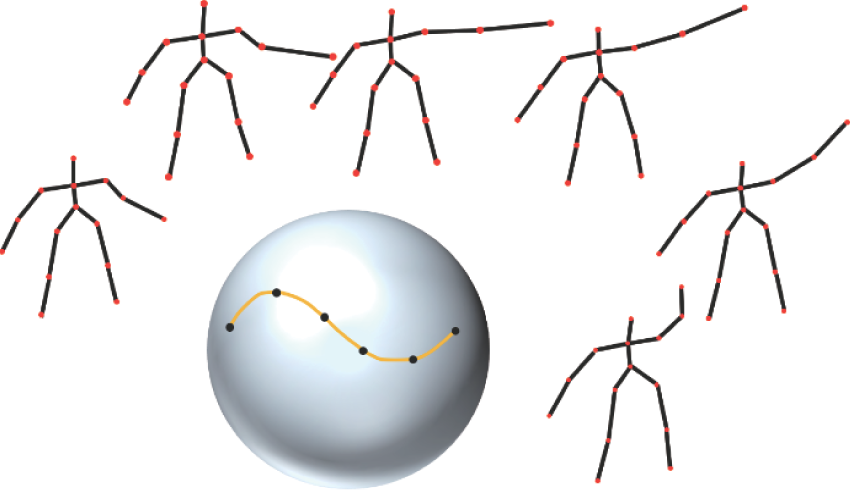
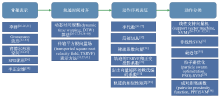
图4
基于流形假设的动作识别框架"
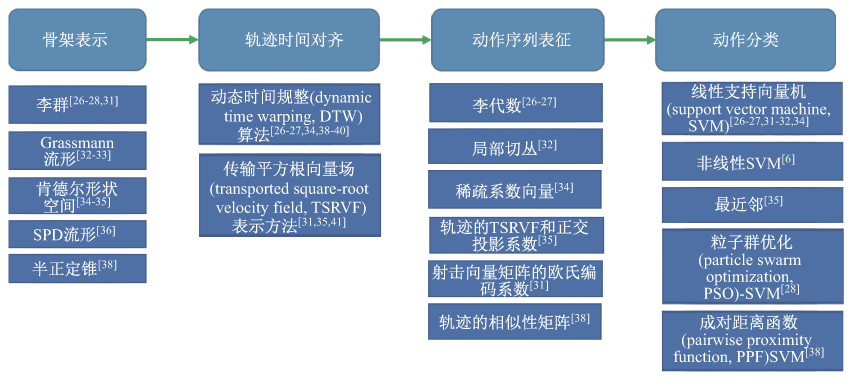
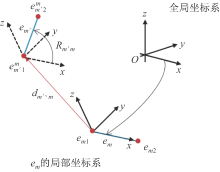
图5
骨骼 ${e}_{{m}'}$ 在 ${e}_{m}$ 局部坐标系下的表示"

图6
挥手动作骨架序列的时间错位"
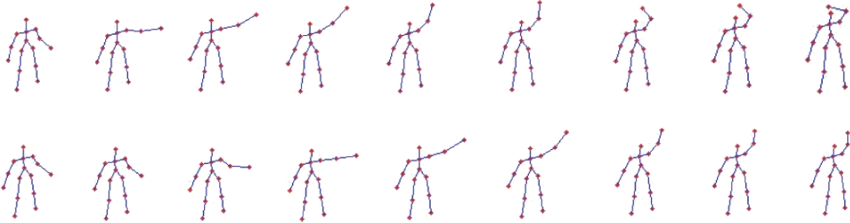
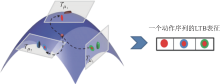
图7
动作序列的LTB表征[30] }"
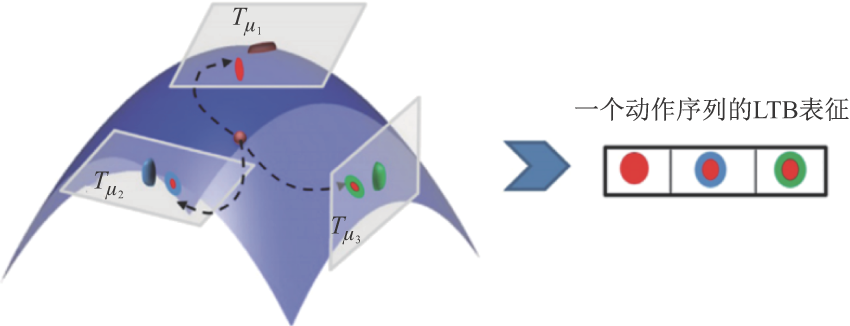

图8
轨迹上点到点的射击向量"
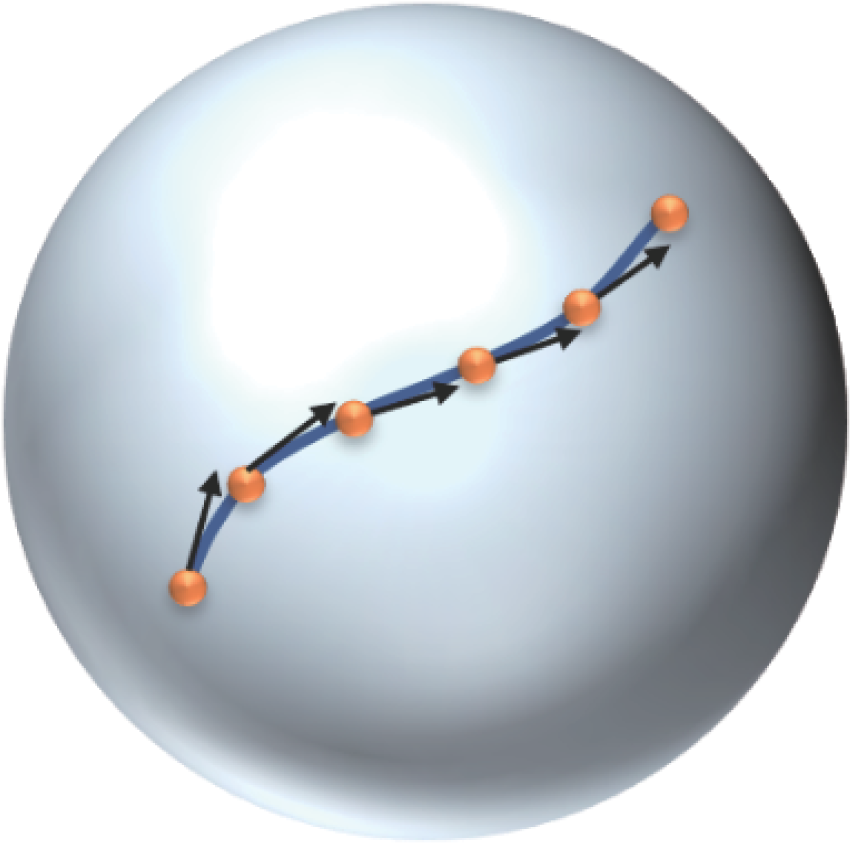
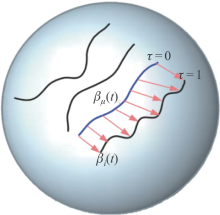
图9
流形上轨迹到轨迹的射击向量[31]"
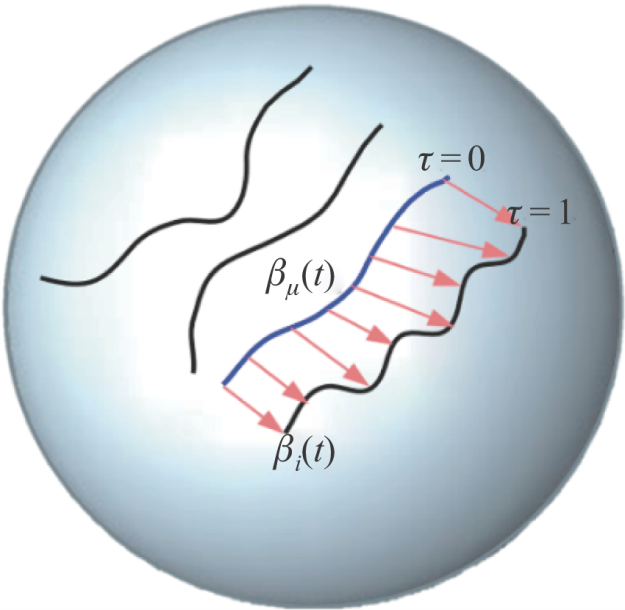

图10
Florence3D数据集中, 动作"bow"的部分骨架序列"


图11
UTKinect 数据集中动作"walk"在两个视角下的部分骨架序列"
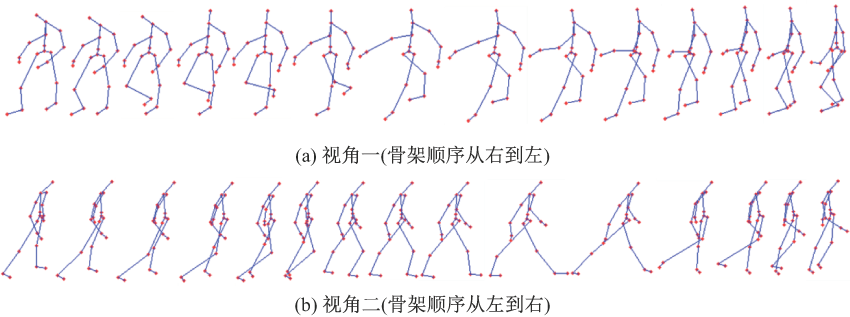

图12
MSR-Action3D 数据集中动作"high arm wave"的部分骨架序列"

表1
基于流形假设的动作识别方法在 Florence3D Action 数据集上的表现"
 |
表2
基于流形假设的动作识别方法在 UTKinect Action 数据集上的表现"
 |
表3
基于流形假设的动作识别方法在 MSR-Action3 数据集上的表现"
 |

图13
中风康复系统[49]"


图14
对摔倒动作的 RGB 图像序列提取骨架序列"

| [1] | Natarajan P, Nevatia R. Online, real-time tracking and recognition of human actions[C]// 2008 IEEE Workshop on Motion and Video Computing. 2008: 1-8. |
| [2] | Yue-Hei Ng J, Hausknecht M, Vijayanarasimhan S, et al. Beyond short snippets: deep networks for video classification[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 4694-4702. |
| [3] | Baek S, Shi Z, Kawade M, et al. Kinematic-layout-aware random forests for depth-based action recognition[EB/OL]. (2016-07-23) [2016-12-09]. http://arxivorg/abs/1607.06972. |
| [4] | Shotton J, Fitzgibbon A, Cook M, et al. Real-time human pose recognition in parts from single depth images[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs: IEEE, 2011: 1297-1304. |
| [5] |
Ke Q, Bennamoun M, An S, et al. Learning clip representations for skeleton-based 3d action recognition[J]. IEEE Transactions on Image Processing, 2018, 27(6): 2842-2855.
doi: 10.1109/TIP.2018.2812099 |
| [6] | Wang L, Zhang J, Zhou L, et al. Beyond covariance: feature representation with nonlinear kernel matrices[C]// Proceedings of the IEEE International Conference on Computer Vision. 2015: 4570-4578. |
| [7] |
Poppe R. A survey on vision-based human action recognition[J]. Image and Vision Computing, 2010, 28(6): 976-990.
doi: 10.1016/j.imavis.2009.11.014 |
| [8] |
Weinland D, Ronfard R, Boyer E. A survey of vision-based methods for action representation, segmentation and recognition[J]. Computer Vision and Image Understanding, 2011, 115(2): 224-241.
doi: 10.1016/j.cviu.2010.10.002 |
| [9] | Wu Z, Yao T, Fu Y, et al. Deep learning for video classification and captioning[M/OL]// Frontiers of multimedia research. [2017-12-09]. https://dl.acm.org/doi/10.1145/3122865.3122867. |
| [10] |
Herath S, Harandi M, Porikli F. Going deeper into action recognition: a survey[J]. Image and Vision Computing, 2017, 60: 4-21.
doi: 10.1016/j.imavis.2017.01.010 |
| [11] | Chu X, Yang W, Ouyang W, et al. Multi-context attention for human pose estimation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1831-1840. |
| [12] | Yang W, Ouyang W, Li H, et al. End-to-end learning of deformable mixture of parts and deep convolutional neural networks for human pose estimation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3073-3082. |
| [13] |
Cao Z, Hidalgo G, Simon T, et al. OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(1): 172-186.
doi: 10.1109/TPAMI.2019.2929257 |
| [14] | Zhang Z. Microsoft kinect sensor and its effect[J]. IEEE Multimedia, 2012, 19(2): 4-10. |
| [15] | Wang Y, Ji Q. A dynamic conditional random field model for object segmentation in image sequences[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2005: 264-270. |
| [16] |
Sminchisescu C, Kanaujia A, Metaxas D. Conditional models for contextual human motion recognition[J]. Computer Vision and Image Understanding, 2006, 104(2/3): 210-220.
doi: 10.1016/j.cviu.2006.07.014 |
| [17] | Wu D, Shao L. Leveraging hierarchical parametric networks for skeletal joints based action segmentation and recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 724-731. |
| [18] | Li W, Wen L, Chang M C, et al. Adaptive RNN tree for large-scale human action recognition[C]// Proceedings of the IEEE International Conference on Computer Vision. 2017: 1444-1452. |
| [19] | Wang H, Wang L. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 499-508. |
| [20] | Ding Z, Wang P, Ogunbona P O, et al. Investigation of different skeleton features for cnn-based 3d action recognition[C]// 2017 IEEE International Conference on Multimedia $\&$ Expo Workshops (ICMEW). 2017: 617-622. |
| [21] |
Xu Y, Cheng J, Wang L, et al. Ensemble one-dimensional convolution neural networks for skeleton-based action recognition[J]. IEEE Signal Processing Letters, 2018, 25(7): 1044-1048.
doi: 10.1109/LSP.2018.2841649 |
| [22] | Wang P, Li Z, Hou Y, et al. Action recognition based on joint trajectory maps using convolutional neural networks[C]// Proceedings of the 24th ACM International Conference on Multimedia. 2016: 102-106. |
| [23] | Yan S, Xiong Y, Lin D. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2018. |
| [24] | Li M, Chen S, Chen X, et al. Actional-structural graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 3595-3603. |
| [25] | Shi L, Zhang Y, Cheng J, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 12026-12035. |
| [26] | Vemulapalli R, Arrate F, Chellappa R. Human action recognition by representing 3d skeletons as points in a lie group[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 588-595. |
| [27] | Vemulapalli R, Chellapa R. Rolling rotations for recognizing human actions from 3d skeletal data[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4471-4479. |
| [28] | Xu D, Xiao X, Wang X, et al. Human action recognition based on Kinect and PSO-SVM by representing 3D skeletons as points in Lie group[C]// 2016 International Conference on Audio, Language and Image Processing (ICALIP). 2016: 568-573. |
| [29] |
Presti L L, La Cascia M. 3D skeleton-based human action classification: a survey[J]. Pattern Recognition, 2016, 53: 130-147.
doi: 10.1016/j.patcog.2015.11.019 |
| [30] | Ren B, Liu M, Ding R, et al. A survey on 3d skeleton-based action recognition using learning method[EB/OL]. (2020-04-14) [2021-04-30]. http://arxiv.org/abs/2002.05907. |
| [31] |
Anirudh R, Turaga P, Su J, et al. Elastic functional coding of Riemannian trajectories[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(5): 922-936.
doi: 10.1109/TPAMI.2016.2564409 |
| [32] |
Slama R, Wannous H, Daoudi M, et al. Accurate 3D action recognition using learning on the Grassmann manifold[J]. Pattern Recognition, 2015, 48(2): 556-567.
doi: 10.1016/j.patcog.2014.08.011 |
| [33] | Hong J, Li Y, Chen H. Variant Grassmann manifolds: a representation augmentation method for action recognition[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2019, 13(2): 1-23. |
| [34] |
Tanfous A B, Drira H, Amor B B. Sparse coding of shape trajectories for facial expression and action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 42(10): 2594-2607.
doi: 10.1109/TPAMI.2019.2932979 |
| [35] | Amor B B, Su J, Srivastava A. Action recognition using rate-invariant analysis of skeletal shape trajectories[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 38(1): 1-13. |
| [36] |
Harandi M T, Hartley R, Lovell B, et al. Sparse coding on symmetric positive definite manifolds using Bregman divergences[J]. IEEE Transactions on Neural Networks and Learning Systems, 2015, 27(6): 1294-1306.
doi: 10.1109/TNNLS.2014.2387383 |
| [37] | Hussein M E, Torki M, Gowayyed M A, et al. Human action recognition using a temporal hierarchy of covariance descriptors on 3D joint locations[C]// Proceedings of International Joint Conference on Artificial Intelligence (IJCAI). 2013: 2466-2472. |
| [38] | Kacem A, Daoudi M, Amor B B, et al. A novel geometric framework on gram matrix trajectories for human behavior understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 42(1): 1-14. |
| [39] | Chaaraoui A, Padilla-Lopez J, Florez-Revuelta F. Fusion of skeletal and silhouette-based features for human action recognition with rgb-d devices[C]// Proceedings of the IEEE International Conference on Computer Vision Workshops. 2013: 91-97. |
| [40] | Müller M, Röder T. Motion templates for automatic classification and retrieval of motion capture data[C]// Proceedings of the 2006 ACM SIGGRAPH/Eurographics Symposium on Computer Animation. 2006: 137-146. |
| [41] | Su J, Kurtek S, Klassen E, et al. Statistical analysis of trajectories on Riemannian manifolds: bird migration, hurricane tracking and video surveillance[J]. Annals of Applied Statistics, 2014, 8(1): 530-552. |
| [42] |
Doretto G, Chiuso A, Wu Y N, et al. Dynamic textures[J]. International Journal of Computer Vision, 2003, 51(2): 91-109.
doi: 10.1023/A:1021669406132 |
| [43] |
Turaga P, Veeraraghavan A, Srivastava A, et al. Statistical computations on Grassmann and Stiefel manifolds for image and video-based recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(11): 2273-2286.
doi: 10.1109/TPAMI.2011.52 pmid: 21422487 |
| [44] |
Kendall D G. Shape manifolds, procrustean metrics, and complex projective spaces[J]. Bulletin of the London Mathematical Society, 1984, 16(2): 81-121.
doi: 10.1112/blms/16.2.81 |
| [45] | Müller M. Information retrieval for music and motion[M]. Heidelberg: Springer, 2007. |
| [46] | Seidenari L, Varano V, Berretti S, et al. Recognizing actions from depth cameras as weakly aligned multi-part bag-of-poses[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2013: 479-485. |
| [47] | Xia L, Chen C C, Aggarwal J K. View invariant human action recognition using histograms of 3d joints[C]// 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. 2012: 20-27. |
| [48] | Li W, Zhang Z, Liu Z. Action recognition based on a bag of 3d points[C]// 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops. 2010: 9-14. |
| [49] | Chen Y, Duff M, Lehrer N, et al. A computational framework for quantitative evaluation of movement during rehabilitation[J]. AIP Conference Proceedings, 2011, 1371(1): 317-326. |
| [50] |
Kwolek B, Kepski M. Human fall detection on embedded platform using depth maps and wireless accelerometer[J]. Computer Methods and Programs in Biomedicine, 2014, 117(3): 489-501.
doi: 10.1016/j.cmpb.2014.09.005 |
| [1] | 李齐柱, 伏霞, 张子旸, 王旭, 陈红梅, 侯春彩, 黄源清, 郭春扬, 闵嘉华. 1.3 $\mu $m InAs/GaAs 量子点侧向耦合浅刻蚀分布反馈激光器[J]. 上海大学学报(自然科学版), 2019, 25(4): 472-483. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||