上海大学学报(自然科学版) ›› 2018, Vol. 24 ›› Issue (5): 730-744.doi: 10.12066/j.issn.1007-2861.1843
陈悦1, 董红斌2, 谭成予1, 梁意文1( )
)
收稿日期:2016-09-23
出版日期:2018-10-30
发布日期:2018-10-26
通讯作者:
梁意文
E-mail:ywliang@whu.edu.cn
基金资助:
CHEN Yue1, DONG Hongbin2, TAN Chengyu1, LIANG Yiwen1()
Received:2016-09-23
Online:2018-10-30
Published:2018-10-26
Contact:
LIANG Yiwen
E-mail:ywliang@whu.edu.cn
摘要:
随着计算机的普及和大数据时代的来临, 个人计算机中文档的版本数急剧增加, 用户想要迅速找到所需的文档绝非易事. 相关研究表明, 文件的起源信息可以为用户提供快速定位目标文档的线索. 已有的一些基于数据起源的检索方式, 其起源粒度多数是文件级的. 但对于内容相关性较高的文档来说, 文件级的起源信息无法清晰地描述内容间的关联关系, 也就无法给予用户充分的帮助. 基于 PROV 模型, 针对文档版本的变化建立内容级的起源概念模型, 并给出了起源词汇表. 在资源描述框架 (resource description framework, RDF) 语言的基础上建立了起源信息的查询访问机制, 并给出了可视化方案, 为用户提供直观的信息表达. 结果表明, 该方法通过对文档检索结果的扩展和解释, 可以为用户提供更有价值的帮助信息, 从而达到快速锁定目标文件的目的, 提高工作效率.
中图分类号:
陈悦, 董红斌, 谭成予, 梁意文. 数据起源在多版本文档检索中的应用[J]. 上海大学学报(自然科学版), 2018, 24(5): 730-744.
CHEN Yue, DONG Hongbin, TAN Chengyu, LIANG Yiwen. Application of data provenance in multi-version documents retrieval[J]. Journal of Shanghai University(Natural Science Edition), 2018, 24(5): 730-744.

图1
PROV概要模型"


图2
教学课件版本内容变化的典型场景"

表1
实体词汇表"
 |
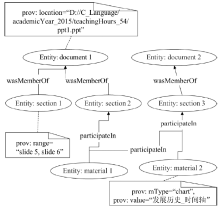
图3
实体起源模型示例"
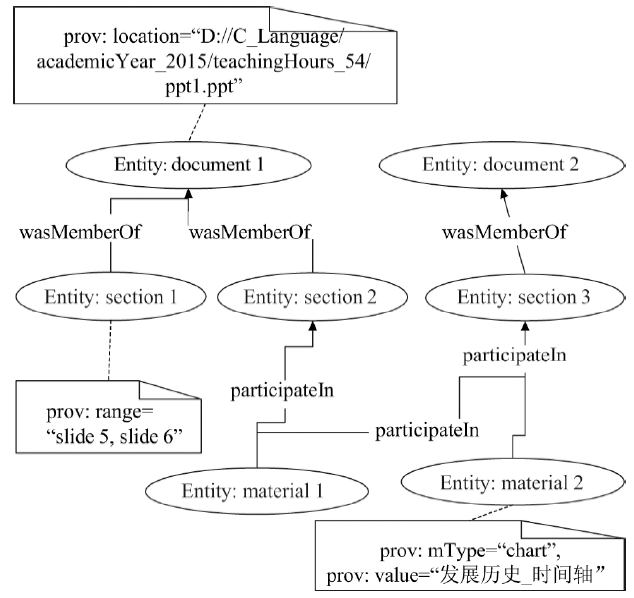
表2
活动词汇表"
 |

图4
活动起源模型示例"
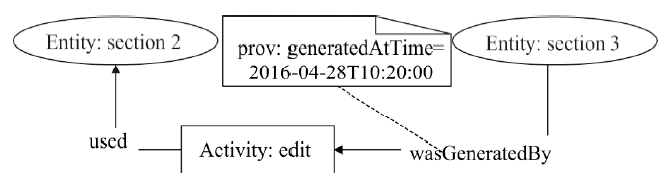

图5
代理起源模型示例"
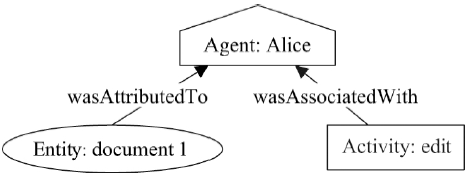
表3
关系词汇表"
 |
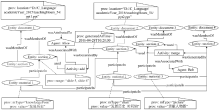
图6
基于PROV的文档版本内容变化过程的起源表示"
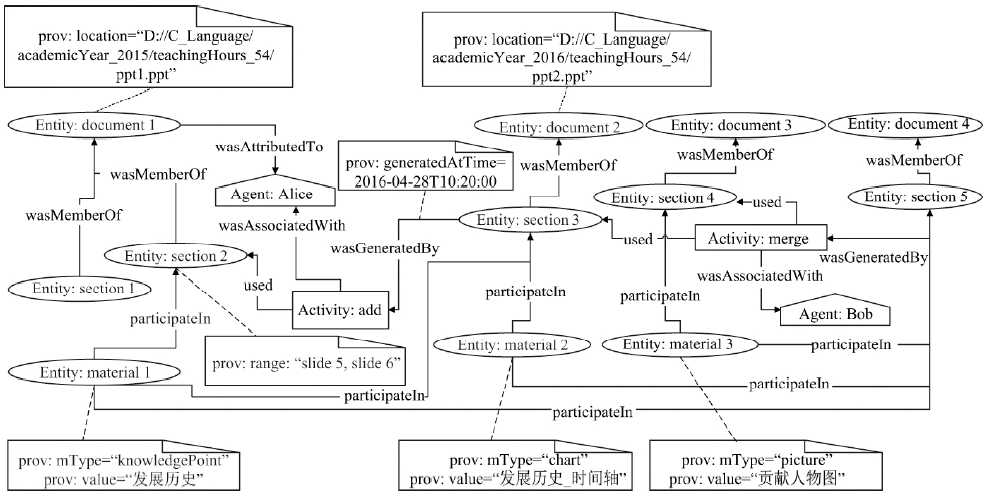
表4
定义及唯一性约束"
 |
表5
不可能性约束和类型约束"
 |

图7
可视化结果展示"
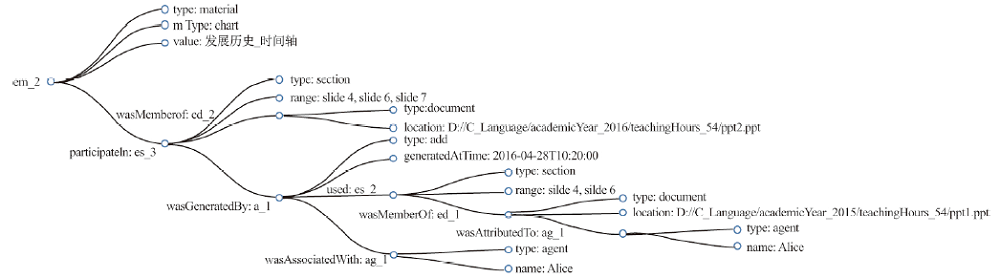

图8
图 7 中部分可视化结果展示"


图9
图 8 中部分可视化结果展示"
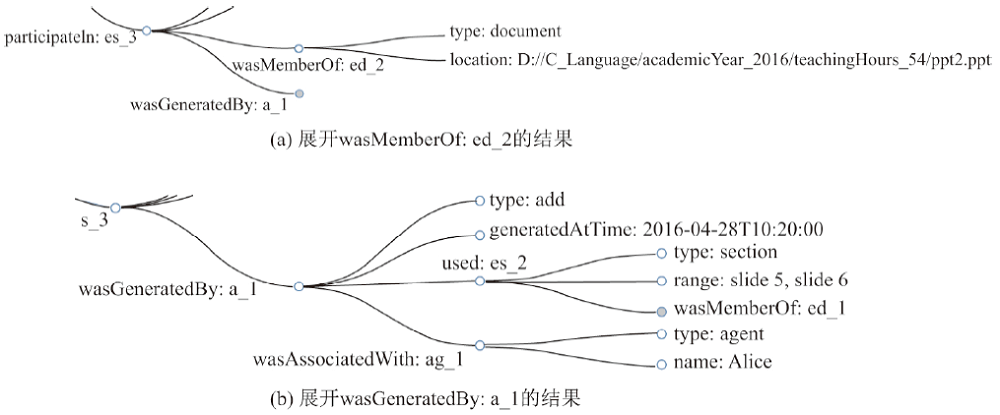

图10
本实验系统总体框架设计"
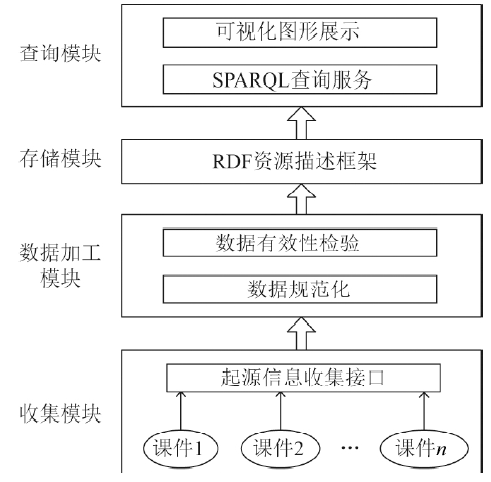
表6
相关实验参数"
 |

图11
实验数据统计"

表7
实验数据统计分析"
 |
| [1] | Lyman P, Varian H R. How much information 2003 [EB/OL]. (2003-10-27)[2016-10-05]. http://www2.sims.berkeley.edu/research/projects/how-much-info. |
| [2] | Blanc-Brude T, Scapin D L. What do people recall about their documents: implications for desktop search tools[C]// Proceedings of the 12th International Conference on Intelligent User Interfaces, ACM. 2007: 102-111. |
| [3] | Shah S, Soules C A N, Ganger G R, et al. Using provenance to aid in personal file search[C]// USENIX Annual Technical Conference. 2007: 171-184. |
| [4] |
Soules C A N, Ganger G R. Connections: using context to enhance file search[J]. ACM SIGOPS Operating Systems Review, 2005,39(5):119-132.
doi: 10.1145/1095809.1095822 |
| [5] | Stumpf S, Fitzhenry E, Dietterich T G. The use of provenance in information retrieval[C]// Workshop on Principles of Provenance. 2007: 20. |
| [6] | Chau D H, Myers B, Faulring A. Feldspar: a system for finding information by association[C]// Proceedings of Personal Information Management. 2008: 131-138. |
| [7] | 戴超凡, 王涛, 张鹏程. 数据起源技术发展研究综述[J]. 计算机应用研究, 2010,27(9):3215-3221. |
| [8] | Rinck M, Hinze A, Bainbridge D, et al. Document DNA: content centric provenance data tracking in documents[C]// Proceedings of the 37th Australasian Computer Science Conference. 2014: 57-66. |
| [9] | Lu C T, Shukla M, Subramanya S H, et al. Performance evaluation of desktop search engines[C]// IEEE International Conference Information Reuse and Integration. 2007: 110-115. |
| [10] | Jensen C, Lonsdale H, Wynn E, et al. The life and times of files and information: a study of desktop provenance[C]// Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, ACM. 2010: 767-776. |
| [11] | Muniswamy-Reddy K K, Holland D A, Braun U, et al. Provenance-aware storage systems[C]// USENIX Annual Technical Conference, General Track. 2006: 43-56. |
| [12] | Dragunov A N, Dietterich T G, Johnsrude K, et al. TaskTracer: a desktop environment to support multi-tasking knowledge workers[C]// Proceedings of the 10th International Conference on Intelligent User Interfaces, ACM. 2005: 75-82. |
| [13] | Yamamoto K, Kuriyama T, Shigemori H, et al. Provenance based retrieval: file retrieval system using history of moving and editing in user experience[C]// Computer Software and Applications Conference. 2011: 618-625. |
| [14] |
Ball R. Don't search, just show me what I did: visualizing provenance of documents and applications[J]. International Journal of Human-Computer Interaction, 2013,29(3):156-168.
doi: 10.1080/10447318.2012.701569 |
| [15] | Luc M, Paolo M. PROV-DM: the PROV data model [EB/OL]. [2016-10-05]. https://www.w3.org/TR/2013/REC-prov-dm-20130430/. |
| [16] | Paul G, Luc M. PROV-overview: an overview of the PROV family of docu- ments [EB/OL]. [2016-10-05]. https://www.w3.org/TR/2013/NOTE-prov-overview-20130430/. |
| [17] | Moreau L, Freire J, Futrelle J, et al. The open provenance model: an over- view[C]// International Provenance and Annotation Workshop. 2008: 323-326. |
| [18] | 倪静, 孟宪学. PROV数据溯源模型及Web应用[J]. 图书情报工作, 2014,58(3):13-19. |
| [19] | Tom D N, James C, Paolo M, et al. Constraints of the PROV data model [EB/OL]. [2016-10-05]. https://www.w3.org/TR/2013/REC-prov-constraints-20130430/. |
| [20] | Eric P, Andy S. SPARQL query language for RDF [EB/OL]. [2016-10-05]. https://www.w3.org/TR/rdf-sparql-query/. |
| [1] | 陆申阳, 冉峰, 郭爱英, 沈华明. 一种用于自适应直方图均衡化的硬件加速器[J]. 上海大学学报(自然科学版), 2020, 26(3): 401-412. |
| [2] | 张婷婷, 张焱, 田丰. VR 影像镜头组接的轴线规则[J]. 上海大学学报(自然科学版), 2019, 25(6): 888-897. |
| [3] | 胡嘉成, 王向阳, 刘晗. 基于深度学习的连铸坯表面缺陷检测[J]. 上海大学学报(自然科学版), 2019, 25(4): 445-452. |
| [4] | 高明柯, 陈一民, 张典华, 黄晨, 李泽宇. 基于改进蚁群算法的血管介入手术路径规划[J]. 上海大学学报(自然科学版), 2019, 25(2): 198-205. |
| [5] | 郁怀波, 胡越黎, 徐杰. 基于多特征融合与树形结构代价聚合的立体匹配算法[J]. 上海大学学报(自然科学版), 2019, 25(1): 66-74. |
| [6] | 张亚军, 刘宗田, 李强, 周文. 面向事件的中文指代语料库的构建[J]. 上海大学学报(自然科学版), 2018, 24(6): 900-911. |
| [7] | 徐敏, 丁友东, 于冰, 李畅, 吴彪, 张婉莹. 基于5${\times}$5邻域像素点相关性的划痕修复算法[J]. 上海大学学报(自然科学版), 2018, 24(5): 686-693. |
| [8] | 黄东晋, 雷雪, 蒋晨凤, 陈燕敏, 丁友东. 基于改进JPS算法的电影群体动画全局路径规划[J]. 上海大学学报(自然科学版), 2018, 24(5): 694-702. |
| [9] | 周敬一, 郭燕, 丁友东. 基于深度学习的中文影评情感分析[J]. 上海大学学报(自然科学版), 2018, 24(5): 703-712. |
| [10] | 黄春晖, 赵其杰, 柯震南. 一种钢坯表面喷印字符图像分割算法[J]. 上海大学学报(自然科学版), 2018, 24(5): 763-772. |
| [11] | 夏天然, 丁友东, 于冰, 黄曦. 基于子帧缝合的老电影大面积破损修复[J]. 上海大学学报(自然科学版), 2018, 24(4): 503-511. |
| [12] | 黄东晋, 李贺娟, 段思文, 肖帆, 丁友东. 基于多自主智能体的电影混战群体仿真[J]. 上海大学学报(自然科学版), 2018, 24(4): 512-523. |
| [13] | 谢志峰, 叶冠桦, 闫淑萁, 何绍荣, 丁友东. 基于生成对抗网络的HDR图像风格迁移技术[J]. 上海大学学报(自然科学版), 2018, 24(4): 524-534. |
| [14] | 田丰, 戴帅凡, 董凤龙, 张芷依, 褚灵伟. 虚拟现实电影中穿越事件对观众感知的影响[J]. 上海大学学报(自然科学版), 2018, 24(4): 535-544. |
| [15] | 吴昊, 张莹, 毛润坤, 董雪婷. 影视对白音质缺陷检测方法[J]. 上海大学学报(自然科学版), 2018, 24(4): 545-552. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||