
收稿日期: 2020-02-03
网络出版日期: 2020-07-16
Improved approach to simultaneous left- and right-hand segmentation from a single depth image
Received date: 2020-02-03
Online published: 2020-07-16
徐正则, 张文俊 . 一种基于深度图像的左右手同步分割改进方法[J]. 上海大学学报(自然科学版), 2021 , 27(3) : 454 -465 . DOI: 10.12066/j.issn.1007-2861.2247
Hand gesture recognition technology based on depth image, which relies on the accurate identification of "clean" hand in the captured depth image, is the primary interactive mode for digital media devices of future generation. We propose an improved approach to simultaneous left- and right-hand segmentation, extending the traditional SegNet algorithm by strategies including class weight, transposed convolution, hybrid dilated convolution, and skip-connection between the encoder and decoder performed by concatenation. Our approach achieves higher F2-Score than the existing baseline by 7.6% for the left and 5.9% for the right hand. The processing on the GPU reaches 20.5 ms per frame at inference time, making real-time hand tracking in depth image sequences feasible. The results of the experiment demonstrate that our approach can considerably improve the performance of simultaneous left- and right-hand segmentation from a single depth map.
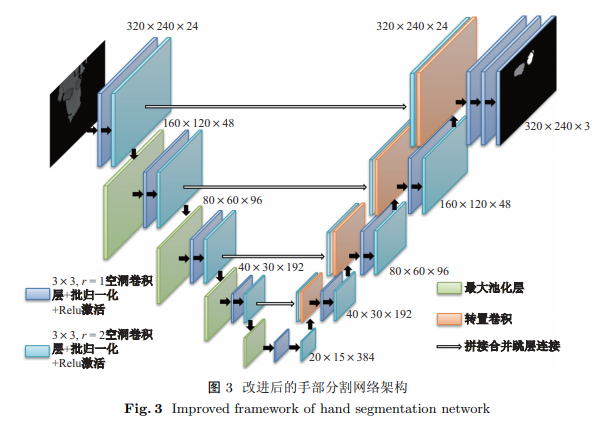
Key words: depth image; hand segmentation; improved approach
| [1] | Ren Z, Yuan J, Zhang Z. Robust hand gesture recognition based on finger-earth mover's distance with a commodity depth camera[C]// ACM International Conference on Multimedia. 2011: 1093-1096. |
| [2] | Tompson J, Stein M, LeCun Y, et al. Real-time continuous pose recovery of human hands using convolutional networks[J]. ACM Transactions on Graphics, 2014,33(5):1-10. |
| [3] | Sinha A, Choi C, Ramani K. Deephand: robust hand pose estimation by completing a matrix imputed with deep features[J]. Computer Vision and Pattern Recognition, 2016(1):4150-4158. |
| [4] | Khan R, Hanbury A, Stttinger J, et al. Color based skin classification[J]. Pattern Recognition Letters, 2012,33(2):157-163. |
| [5] | Melax S, Keselman L, Orsten S. Dynamics based 3D skeletal hand tracking[C]// Proceedings of Graphics and Interface. 2013: 63-70. |
| [6] | Sridhar S, Oulasvirta A, Theobalt C. Interactive markerless articulated hand motion tracking using RGB and depth data[C]// IEEE International Conference on Computer Vision. 2013: 2456-2463. |
| [7] | Intel. Intel RealSense SDK for Windows [EB/OL]. [2020-01-20]. https://software.intel.com/en-us/articles/realsense-sdk-windows-eol. |
| [8] | Oikonomidis I, Kyriazis N, Argyros A. Efficient model-based 3D tracking of hand articulations using kinect [C]// The British Machine Vision Conference. 2011: 101.1-101.11. |
| [9] | Romero J, Kjellstrom H, Kragic D. Monocular real-time 3D articulated hand pose estimation[C]// IEEE-RAS International Conference on Humanoid Robots. 2009. |
| [10] | Shotton J, Sharp T, Kipman A. Real-time human pose recognition in parts from single depth images[J]. Communications of the ACM, 2013,56(1):116-124. |
| [11] | Sharp T, Keskin C, Robertson D P, et al. Accurate, robust, and flexible real-time hand tracking[C]// ACM Conference on Human Factors in Computing Systems. 2015: 3633-3642. |
| [12] | Srinath S, Franziska M, Antti O, et al. Fast and robust hand tracking using detection-guided optimization[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2015: 3213-3221. |
| [13] | Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2014: 580-587. |
| [14] | Girshick R. Fast R-CNN[C]// IEEE International Conference on Computer Vision. 2015: 1440-1448. |
| [15] | Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// IEEE Transactions on Pattern Analysis and Machine Intelligence. 2017: 1137-1149. |
| [16] | Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779-788. |
| [17] | Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6517-6525. |
| [18] | Redmon J, Farhadi A. YOLOv3: an incremental improvement[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2018. |
| [19] | James S S Ⅲ, Rogez G, Yang Y, et al. Depth-based hand pose estimation: data, methods, and challenges[C]// IEEE International Conference on Computer Vision. 2015: 1868-1876. |
| [20] | Shelhamer E, Long J, Darrell T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39(4):640-651. |
| [21] | Noh H, Hong S, Han B. Learning deconvolution network for semantic segmentation[C]// IEEE International Conference on Computer Vision. 2015: 1520-1528. |
| [22] | Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39:2481-2495. |
| [23] | Eigen D, Fergus R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]// IEEE International Conference on Computer Vision. 2015: 2650-2658. |
| [24] | Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine, 2018,40(4):834-848. |
| [25] | Wang P, Chen P F. Understanding convolution for semantic segmentation[C]// IEEE Winter Conference on Applications of Computer Vision. 2018: 1451-1460. |
| [26] | He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778. |
| [27] | Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing and Computer. 2015: 234-241. |
| [28] | Xu C, Cheng L. Efficient hand pose estimation from a single depth image[C]// IEEE International Conference on Computer Vision. 2013: 3456-3462. |
| [29] | Tompson J, Stein M, Lecun Y, et al. NYU hand pose dataset [EB/OL]. [2020-01-20]. https://jonathantompson.github.io/NYU_Hand_Pose_Dataset.htm. |
| [30] | Saric M. LibHand: a library for hand articulation [EB/OL]. [2020-01-20]. http://www.libhand.org/. |
| [31] | Zimmermann C, Brox T. Rendered handpose dataset [EB/OL]. [2020-01-20]. https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html. |
| [32] | Wetzler A, Slossberg R, Kimmel R. HandNet [EB/OL]. [2020-01-20]. http://www.cs.technion.ac.il/~twerd/HandNet/. |
/
| 〈 |
|
〉 |