
收稿日期: 2019-03-27
网络出版日期: 2019-10-28
Text classification model based on essential $n$-grams and gated recurrent neural network
Received date: 2019-03-27
Online published: 2019-10-28
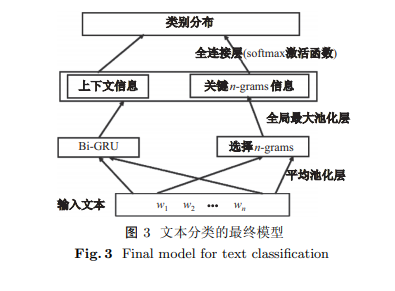
提出一种基于关键 $n$-grams 和门控循环神经网络的文本分类模型. 模型采用更为简单高效的池化层替代传统的卷积层来提取关键的 $n$-grams 作为重要语义特征, 同时构建双向门控循环单元(gated recurrent unit, GRU)获取输入文本的全局依赖特征, 最后将两种特征的融合模型应用于文本分类任务. 在多个公开数据集上评估模型的质量, 包括情感分类和主题分类. 与传统模型的实验对比结果表明: 所提出的文本分类模型可有效改进文本分类的性能, 在语料库 20newsgroup 上准确率提高约 1.95%, 在语料库 Rotton Tomatoes 上准确率提高约 1.55%.
赵倩, 吴悦, 刘宗田 . 基于关键 $n$-grams 和门控循环神经网络的文本分类模型[J]. 上海大学学报(自然科学版), 2021 , 27(3) : 544 -552 . DOI: 10.12066/j.issn.1007-2861.2158
An effective text classification model based on $n$-grams and a gated recurrent neural network is proposed in this paper. First, we adopt a simpler and more efficient pooling layer to replace the traditional convolutional layer to extract the essential $n$-grams as important semantic features. Second, a bidirectional gated recurrent unit (GRU) is constructed to obtain the global dependency features of the input text. Finally, we apply the fusion model of the two features to the text classification task. We evaluate the quality of our model on sentiment and topic categorization tasks over multiple public datasets. Experimental results show that the proposed method can improve text classification effectiveness compared with the traditional model. On accuracy, it approaches an improvement of 1.95% on the 20newsgroup and 1.55% on the Rotten Tomatoes corpus.
| [1] | Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[C]// 15th Conference of the European Chapter of the Association for Computational Linguistics. 2017: 427-431. |
| [2] | Li B F, Zhao Z, Liu T, et al. Weighted neural bag-of-$n$-grams model: new baselines for text classification[C]// Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics. 2016: 1591-1600. |
| [3] | Kim Y. Convolutional neural networks for sentence classification[C]// 2014 Conference on Empirial Methods in Natural Language Processing. 2014: 1746-1751. |
| [4] | Conneau A, Schwenk H, Barrault L, et al. Very deep convolutional networks for text classification[C]// 15th Conference of the European Chapter of the Association for Computational Linguistics. 2017: 1107-1116. |
| [5] | Kolen J, Kremer S. Gradient flow in recurrent nets: the difficulty of learning long term dependencies [M]. Piscataway: Wiley-IEEE Press, 2001. |
| [6] | Tang D, Qin B, Liu T. Document modeling with gated recurrent neural network for sentiment classification[C]// Conference on Empirical Methods in Natural Language Processing. 2015: 1422-1432. |
| [7] | Abreu J, Fred L, David M, et al. Hierarchical attentional hybrid neural networks for document classification[C]// International Conference on Artificial Neural Networks. 2019: 396-402. |
| [8] | Hsu S T, Moon C, Jones P, et al. A hybrid CNN-RNN alignment model for phrase-aware sentence classification[C]// 15th Conference of the European Chapter of the Association for Computational Linguistics. 2017: 443-449. |
| [9] | Pang B, Lee L. Seeing stars: exploiting class relationships for sentiment categorization with respect to rating scales[C]// 43rd Annual Meeting of the Association for Computational Linguistics. 2005: 115-124. |
| [10] | Maas A L, Daly R E, Pham P T, et al. Learning word vectors for sentiment analysis[C]// 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. 2011: 142-150. |
| [11] | Johnson R, Zhang T. Effective use of word order for text categorization with convolutional neural networks[C]// 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2015: 103-112. |
| [12] | Mcauley J, Leskovec J. Hidden factors and hidden topics: understanding rating dimensions with review text[C]// ACM Conference on Recommender Systems. 2013: 165-172. |
| [13] | Dai A M, Le Q V. Semi-supervised sequence learning[J]. Advances in Neural Information Processing Systems, 2015,2015:3079-3087. |
| [14] | Kingma D P, Ba J. Adam: a method for stochastic optimization[C]// 3rd International Conference for Learning Representations. 2015. |
/
| 〈 |
|
〉 |